谷歌、Anthropic双重围剿下的OpenAI,正面临「生死抉择」
谷歌、Anthropic双重围剿下的OpenAI,正面临「生死抉择」进入到 2026 年,OpenAI 在关注消费级产品(如 ChatGPT、社交应用)之外,开始将一部分重心转向企业级市场。
来自主题: AI资讯
9913 点击 2026-01-26 15:00
 搜索
搜索
进入到 2026 年,OpenAI 在关注消费级产品(如 ChatGPT、社交应用)之外,开始将一部分重心转向企业级市场。
提供软件支撑OpenAI 等公司语音、视频及实体 AI 模型的初创企业 LiveKit,在一轮融资中筹集了 1 亿美元,公司估值达 10 亿美元。LiveKit 的软件和网络运行着利用语音、视频以及所谓物理 AI(应用于机器人技术等任务)的人工智能模型。

有没有发现,大厂都在布局自己的AI硬件产品。 在达沃斯现场,OpenAI 的全球事务官克里斯·莱恩透露了一个最新消息,OpenAI 正在按计划推进,准备在 2026 年下半年推出首款 AI 硬件设备。
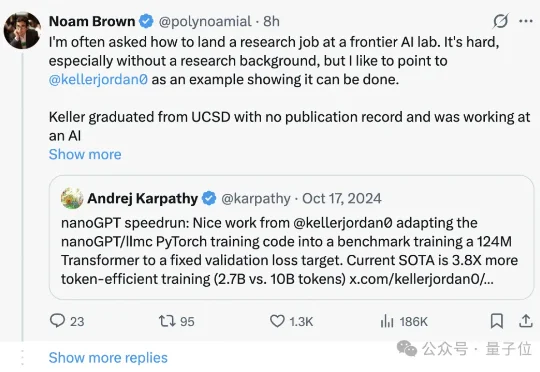
如果没有PhD,是不是就和前沿AI研究没关系了?至少在Noam Brown看来,未必。这位OpenAI 研究员、o1的核心贡献者,刚刚分享了一串“非典型研究员”的经历。

2026年1月,前OpenAI CTO Mira Murati创办的明星公司Thinking Machines Lab遭遇「灭顶之灾」:联合创始人Barret Zoph因办公室恋情丑闻被降职后心生不满,联合另外两名核心骨干向Mira逼宫索权,遭拒后被当场开除。然而仅不到一小时,三人便集体叛逃回OpenAI,在老东家的迎接下风光回朝。
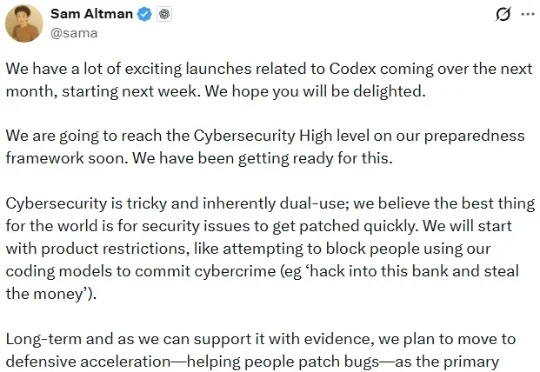
刚刚,OpenAI CEO 山姆・奥特曼发了一条推文:「从下周开始的接下来一个月,我们将会发布很多与 Codex 相关的激动人心的东西。」他尤其强调了网络安全这个主题。

编辑|杜伟、泽南 今天一早,OpenAI CEO 奥特曼就发推晒收入,「仅我们的 API 业务而言,上个月就增加了超过 10 亿美元的 ARR(年度经常性收入)。」 他继续说到,大多数人只看到了 Ch
就在最近,OpenAI 终于把"丹炉"和"配方"都端出来了。OpenAI Academy 悄悄上线了一个名为 Prompt Packs(提示词包) 的资源库。

OpenAI 收购 Torch Health 这件事,这两天我看到很多解读,基本都落在两个方向。一个是人才收购,四个人的小团队,买回去做 ChatGPT Health 的一块拼图。另一个是医疗布局,OpenAI 终于开始认真做垂直行业了。

由三位前 OpenAI 研究人员创立的初创公司 Applied Compute 正就以 13 亿美元估值筹集新资金进行谈判,包括该项投资在内。据透露,该公司致力于帮助企业使用自有数据定制模型。若融资成功,其估值将较不到三个月前公布的上一轮融资( 估值约 5 亿美元 )增长逾一倍。